Paper Oral Presentation Slides Code Pgeon Library BlueSky Linkedin
Abstract
Agents are a special kind of AI-based software in that they interact in complex environments and have increased potential for emergent behaviour. Explaining such behaviour is key to deploying trustworthy AI, but the increasing complexity and opaque nature of many agent implementations makes this hard. In this work, we reuse the Policy Graphs method –which can be used to explain opaque agent behaviour– and enhance it to query it with hypotheses of desirable situations. These hypotheses are used to compute a numerical value to examine agent intentions at any particular moment, as a function of how likely the agent is to bring about a hypothesised desirable situation. We emphasise the relevance of how this approach has full epistemic traceability, and each belief used by the algorithms providing answers is backed by specific facts from its construction process. We show the numeric approach provides a robust and intuitive way to provide telic explainability (explaining current actions from the perspective of bringing about situations), and allows to evaluate the interpretability of behaviour of the agent based on the explanations; and it opens the door to explainability that is useful not only to the human, but to an agent.
Video explanation
Motivating example
Consider the following scenario. You are watching a chef work in the kitchen. He toils away at the cutting board, prepares ingredients over the counter-top… until you see him fill a cooking pot with water. You surmise that it will take part in the recipe, possibly to boil water and do something with it. You ask the chef: Why did you feel that pot? Befuddlingly, he responds:
Because the hob was unused, and the pot was empty.
This kind of responses are a staple of explainable agency. Especially when working with explaining opaque agents, or coming up with agent-agnostic methods, explainable agency focuses on which elements of the current state seem to be relevant for the action (in this case, filling the pot). Rather than illuminate the explainee, it leaves them confused. Instead, what he’d have expected would be something akin to:
Because I am going to cook pasta.
We humans are able to attribute that sort of intentionality easily, simply via observation: without the need to ask, by simply observing the counter top and locating the dry pasta, we could have arrived at the same conclusion. Moreso, the task of cooking pasta, albeit desirable (who doesn’t love some good carbonara), is not the sole reason of existence of the cook: therefore, when doing this attribution, we would be hypothesising that such seems desirable and is going to happen.
We should also take into consideration that, even if such a desire or goal existed, there may be things (such as) the building catching fire) that would result in the desire not being fulfilled. Hence, it would be nice to also know how much intention is there behind the actions: will he stop making pasta if he gets a phone call that a friend is bringing take-out? Has he already cooked some spoilables, and hence is determined to use them despite the call?
With these questions in mind, we want a model that, like humans, is capable of attributing intentions, and can be used to reference desires, milestones, goals, etc. that an explainee will understand as part of their outcome. When we have these intentions, we will be able to reply to questions like:
- What do you intend to do now? I intend to boil water, cook pasta, and serve a plate of carbonara.
- Why are you filling the pot with water? I need it to boil water.
- How are you going to boil water? I will place the pot with water on the hob, turn it on, then go back to chopping the guanciale. By the time I end, the water will be boiling.
Intention Policy Graphs (IPG)
IPGs are a simple model for understanding telic (that is, long-term) agent behaviour. The gist is: if an explainee would understand that an agent acts to achieve something apparently desirable, then providing responses that summarise behaviour as ‘bringing about’ such achievement can explain actions.
Rather than assume that the agent tracks these desirable things, we approach it from an architecture-agnostic perspective: What is needed to know if agent behaviour will bring about some desirable state? Motivated by folk-psychology, we consider the eponymous intentions, which are the result of the desire to achieve something together with a belief it can be attained.
In this work, we operationalise intention as the probability that a desire be fulfilled in the future of a given state. We use Policy Graphs (PG) as a model to estimate probabilities of actions and transitions (P(s’|a,s), P(a|s)) such that we can compute the probability of any trajectory culminating on a desirable transition in the graph, for any possible state: for a desire d, and a state s, there is an intention Id(s) (which follows axioms of probability).
XAI questions, evaluation and metrics
In order to evaluate that an intention occurs, we impose a commitment threshold C as the minimum intention that a state needs in order to say that an intention is attributed to the agent in a state. This doubles as a trade-of between interpretability and reliability. At higher C, the explainee is skeptic toward explanations, intentions are less often attributed (and hence part of answers to explainability), but they are more frequently intentions that come to be fulfilled. Handling and studying the trade-of is explained in the following section.
We use this intention to answer questions such as:
- What does the agent intend to do at state s? Any intention that is attributed in s (Id(s)>C).
- Why would it do a at s? The intentions attributed in s that are expected to increase by using a
- How would the agent fulfill d from s? A plausible sequence of actions and states the PG believes will occur such that d is brought about, starting at s.

‣ What does it intend to do?
Desire to SERVE SOUP: 0.625
‣ Why would it INTERACT?
Intentions attributed for SERVING SOUP
expected to increase by 0.05.
‣ How would it fulfill its desire?
By performing the following chain of actions:
INTERACT → DOWN → RIGHT
→ DOWN → INTERACT

‣ What does it intend to do?
Desire to PUT ONION IN POT: 0.381
‣ Why would it INTERACT?
Intentions attributed for PUTTING ONION IN
POT expected to increase by 0.31.
‣ How would it fulfill its desire?
By performing the following chain of actions:
INTERACT → RIGHT → INTERACT
Metrics
In order to study the trade-of, we simply compute two metrics:
- Attributed Intention Probability: What is the probability that, at some point during execution, I am in a state that could answer explainability questions (regarding intention)? Ie. what is the probability that the state any (ie. at least one) intention above the commitment threshold? At lower thresholds, there is more attributed intention probability, we can ask more often, and the behaviour is more interpretable (even if the interpretation is incorrect).
- Expected Intention Probability: What is the probability that, once an intention is attributed to the agent, that it will be fulfilled? Note that, since intention is already that probability, what we are effectively computing is the expected intention value. At higher commitment thresholds, there will be less lower-intention states with attributed intention and hence higher expected intention; which translates in explanations being more often correct in what the agent will do.
The value and trade-off between either is domain and even agent-dependant. In order to pick the most adequate commitment threshold, a ROC curve may be used to pick the most convenient threshold for a particular explainee or use-case.
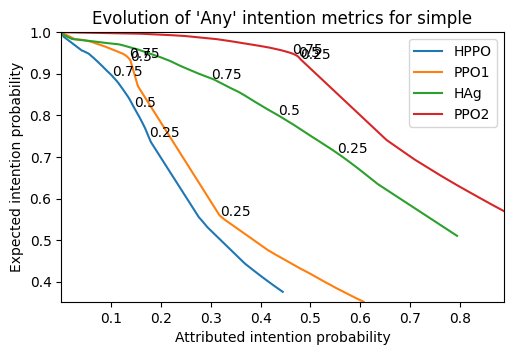
For the sake of our experiments, we always picked a commitment-threshold of 0.5, as it is reasonably high for reliability (above 80% for all cases), whilst providing reasonably high interpretability.
In this plot, we can see a distinct difference in behaviour between the agents too: the higher the line stays, the more ‘rational’ an agent appears. The PPO pair is the most well-performing (in terms of rewards): and PPO2 provides the highest explainability metrics. However, what the plot shows is that both agents HPPO and PPO1 (each of a different pair of agents tested together) are instead the ones below. Luckily, intentions can be used to debug or understand what is actually happening:
The metrics introduce above are computed for the existence of ‘any’ intention being attributed. If instead they are computed for a particular desire, we can see how the agent acts toward individual goals.
For a given commitment-threshold of 0.5, here we show the PPO pair of the plot above:
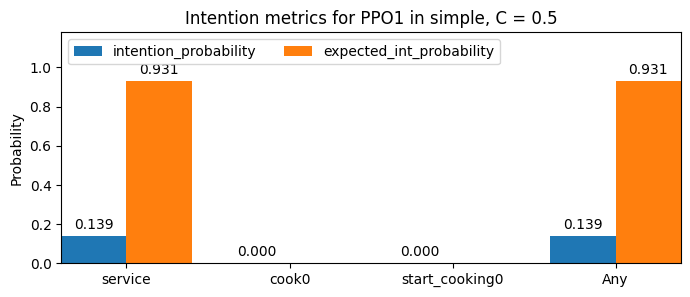
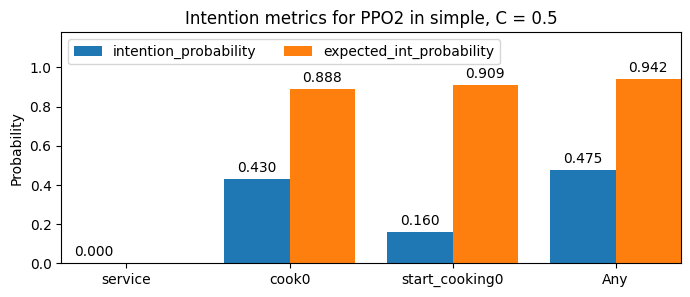
As we can see, the agents specialise between cooking (putting onions in the pot), and servicing! One can easily come up with an hypothesis of why this happens (when you know the game): the agents can collide with each-other, and in the cramped space of this layout, they would hinder each other were they both cooking or servicing. Therefore, agents don’t appear to behave ‘rationally’ with respect to the hypothesised desires during part of the time (with servicing being the least common). We could add further desires to understand this better: for example, a desire to not be on the row of space closest to the pots when they are not doing their task.
This can be used to debug both the agent and the explainability hypotheses.
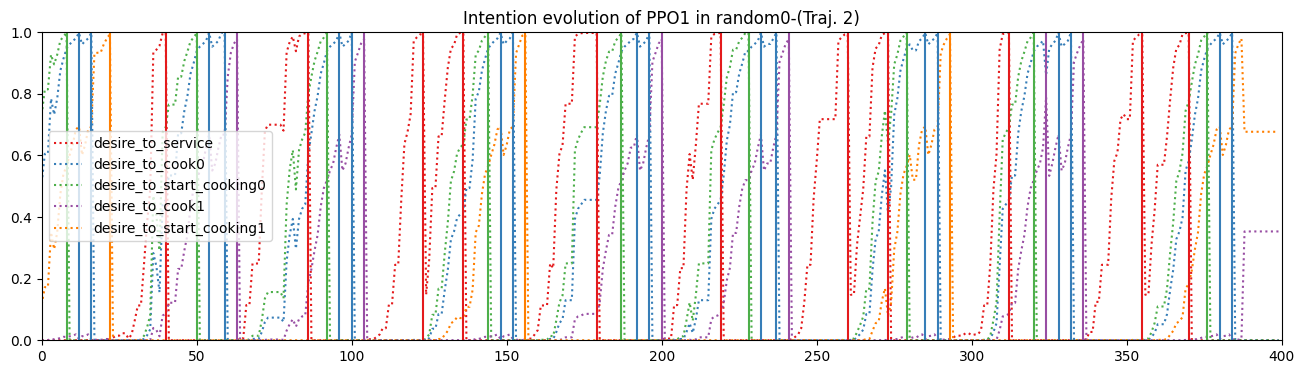
Finally, for a more ‘visual’ inspection, either the gif from the video or the plot below are useful tools to see intention progression through time, as the agent interacts with the environment, to as an alternate, visual explanation of agent behaviour.
Conclusions
We introduce the notion of intention as a way to explain any agent architecture, understood as ‘the probability that an agent will bring about some desirable thing’. We do this motivated by the folk-conceptual theory of explanations, where intentions are both desire and belief of desire attainability. In our case, desires are explainee-dependant (so that the answer can be interpretable), and beliefs are grounded in a frequentist approach ensuring truthfulness, converting them to probabilities. We allow to trade-off interpretability and reliability with a tunable threshold, and provide metrics and tools for evaluating the technique.
We apply it successfully to the Overcooked environment, with both artificial agents and even a simulacra of a human agent.
Related work we’ve done
This work is contextualised by how we believe explanation in agents should look like, being a particular rung in a Ladder of Intentions (EXTRAAMAS’25), exploring one of the many facets of explainability in agents.
Furthermore, beyond the case of Overcooked, this work has also been applied to non-artificial agents in a much more complex environment: human drivers in the real world, in Explaining Autonomous Vehicles with IPGs (EXTRAAMAS’25).
Cite as
@inproceedings{gimenez_intention_aware_2025,
author = {Gimenez-Abalos, Victor and Alvarez-Napagao, Sergio and Tormos, Adrian and Cortés, Ulises and Vázquez-Salceda, Javier},
title = {Policy Graphs and Intention: answering ‘why’ and ‘how’ from a telic perspective},
year = {2025},
isbn = {},
publisher = {International Foundation for Autonomous Agents and Multiagent Systems},
address = {Richland, SC},
abstract = {},
booktitle = {Proceedings of the 24rd International Conference on Autonomous Agents and Multiagent Systems},
pages = {},
numpages = {},
keywords = {},
location = {Detroit, United States of America},
series = {AAMAS '25}
}